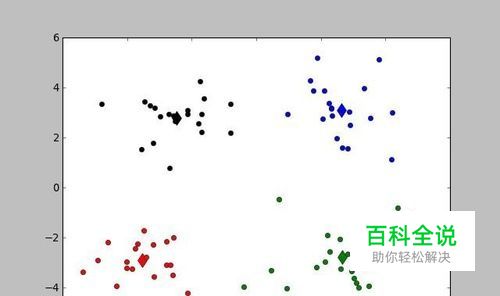
k-means 算法接受参数 k ;然后将事先输入的n个数据对象划分为 k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。聚类相似度是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算的。通过随机选取几个聚类中心,并计算所有点到中心的距离,选取最近的一类,在以这个簇为中心,求簇中点的均值形成新的类。